
Table of contents of the article:
Kubernetes has presumably won the container wars. However, Kubernetes is still difficult and causes a lot of pain.
I think I should give a little preface to this article. Kubernetes is the new runtime for many applications, and when used correctly it can be a powerful tool for getting complexity out of your development lifecycle. However, in recent years I have seen many people and companies stumble upon the desire to manage their own installation. It often remains in the experimental phase and never goes into production.
How does Kubernetes work?
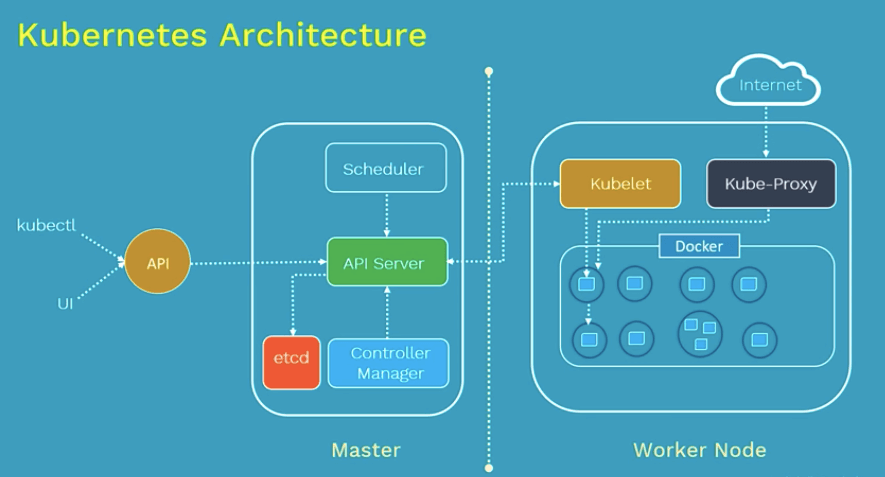
In large parts, Kubernetes or K8s appear to be very simple. The nodes (machines) on which Kubernetes runs are divided into (at least) two types: the master and the workers. The master (s), by default, do not perform any actual workload, this is the work of the workers. The Kubernetes master includes a component called API server which provides an API you can talk to using kubectl. It also includes a planner, which makes decisions about which container should run where (schedule containers). The final component is the controller-manager, which is actually a set of multiple controllers responsible for managing node outages, managing replicas, merging services and pods (sets of containers), and finally managing accounts. service and API access tokens. All data is stored in etcd, which is a highly consistent key value database (with some really interesting features). So, to summarize, the master is responsible for managing the cluster. No wonder. The worker, on the other hand, is handling the actual workloads. To this end, it includes, once again, a number of components. First of all, it runs the kubelet, which is again an API that works with containers on that node. There is also the kube-proxy, which forwards network connections, containerd to run container, and depending on the configuration there may be other things like kube-dns or gVisor. You will also need some sort of overlay network or integration with your underlying network configuration so that Kubernetes can manage the network between your pods.
Kubernetes ready for production
This, so far, doesn't sound too bad. Install a couple of programs, configurations, certificates, etc. Don't get me wrong, it's still a learning curve, but it's nothing an average sysadmin hasn't dealt with in the past. However, the simple manual installation of Kubernetes isn't exactly production ready, so let's talk about the steps involved in getting this thing up and running. First, the installation.
You really want to have some sort of automated installation. It doesn't matter if it's Ansible, Terraform, or other tools, you want it to be automated. kops, for example, helps with this, but using kops means you don't know exactly how it's set up and can cause problems when you want to debug something later. This automation should be tested and tested regularly. Next, you need to monitor the Kubernetes installation. So right away you need something like Prometheus, Grafana, etc. Do you run it inside your Kubernetes? If your Kubernetes has a problem, is your monitoring interrupted? Or do you manage it separately? If so, then where do you manage it?
Also noteworthy are the backups.
What will you do if your master crashes, the data is unrecoverable, and you need to restore all pods on the system? Have you tested how long it takes to run all the jobs in your system again? Do you have a disaster recovery plan? Now, since we are talking about the CI system, we need to run a Docker registry for the images. This, of course, can be done again in Kubernetes, but if Kubernetes crashes. The CI system is obviously an issue too, as is the version control system. Ideally, isolated from your production environment so that if that system has a problem, at least you can access your git, redeploy, etc.
Data Storage
Let's talk about the elephant in the room: memorization. Kubernetes in and of itself does not provide a storage solution. Of course, it is possible to mount a folder from the host machine, but this is neither recommended nor simple. Rok, for example, makes it relatively easy to use Ceph as the underlying block memory for your data storage needs, but my experience with Ceph is that it has a lot of values and configurations that need tuning, so you're not out of the question at all. trouble simply advancing to the next step.
Debugging
When talking about Kubernetes with developers, a common pattern showed up quite regularly: when using a managed Kubernetes, people had trouble debugging their applications. Even simple problems, such as a container failing to start, have caused confusion. This, of course, is an education problem. In recent decades, developers have learned how to debug "classic" configurations: reading log files in / var / log, etc. but with containers we don't even know which server the container is running on, so it presents a paradigm shift.
The complexity problem
You may have noticed that I'm skipping the things cloud providers give you, even if it's not a fully managed Kubernetes. Of course, if you're using a Kubernetes managed solution, that's great, and you don't need to worry about any of that, except debugging. Kubernetes has a lot of moving parts, and Kubernetes alone doesn't provide a full stack of solutions. RedHat OpenShift, for example, does this, but it costs and you still have to add things yourself. Right now Kubernetes is on the hill of Gartner's hype cycle, everyone wants it, but few truly understand it. In the next few years, several companies will need to realize that Kubernetes is not the solution to all ills and understand how to use it correctly and efficiently.
I think getting your Kubernetes running is only worth it if you can afford to dedicate an operations team to the issue of maintaining the underlying platform for your developers.